Introduction à la corrélation et à la régression linéaire
L'objectif de cette page interactive est de permettre une meilleure compréhension des notions de corrélation et de régression linéaire. Elle est à destination des géographes qui rencontreraient des difficultés dans la compréhension de ces notions ou qui souhaiteraient simplement s'y instruire de manière la plus interactive possible en passant par des exemples géographiques simples.
Cette page s'appuie sur un tableau d'information géographique simple. Il s'agit de la répartition de différentes catégories socio-professionnelles au sein des départements de France métropolitaine. On ne discutera pas ici de la pertinence de ce choix : répartition de la population en 8 catégories socio-professionnelles étudiée à l'échelle départementale. Le fichier Excel et le shapefile peuvent être téléchargés ici si vous voulez explorer les données avec vos propres outils. Ci-dessous, un extrait de ce tableau d'information géographique où pour chaque département, nous disposons du nombre d'agriculteurs, de cadres, d'employés...
Voir le tableau d'information géographique complet
On peut aussi explorer les données spatialement comme dans la représentation ci-dessous. En passant sur chaque département, vous pouvez visualiser les données et même afficher des diagrammes radars :
Exploration univariée : Derrière les variations, beaucoup de ressemblances
Il est bien entendu parfaitement possible d'étudier chaque catégorie socio-professionnelle indépendamment et donc de faire ce que l'on appelle de la statistique univariée. D'ailleurs, lorsque l’on fait de la statistique multivariée (de la statistique multidimensionnelle c'est la même chose), il est en fait nécessaire et conseillé de bien connaitre chaque variable et donc d'utiliser les outils de la statistique univariée avant de passer à l'analyse multivariée. Ici, on pourra par exemple nous reprocher de ne pas normaliser (centrer/réduire) ces données, de travailler sur des données de stock... Néanmoins, ces choix vont nous permettre ici d'illustrer simplement l'intérêt des régressions et des corrélations.
> A noter que nous allons considérer chaque catégorie socio-professionnelle comme des variables, ce qui est critiquable, car on pourrait statistiquement les considérer comme différentes modalités d'une variable qualitative. On aurait alors un tableau de contingence.
Voir le tableau des résumés statistiques
Voir les boites à moustache
Pour la suite, ce qu'il faut retenir :
Il y a une grande disparité entre ces variables, par exemple il y a peu d'agriculteurs et beaucoup d'employés ;
Ces variables sont caractérisées par une forte variance (écart-type), c'est à dire qu'il y a de fortes disparités entre les départements, notamment les cadres qui se concentrent à Paris et sont peu présents dans beaucoup de départements ;
Les agriculteurs sont répartis plus équitablement (moins de variance) que les autres catégories socio-professionnelles.
Pour chaque variable, on pourra réaliser une carte thématique. Pour cela, sachant que l'on travaille sur des données quantitatives de stock, il convient d'utiliser des symboles proportionnels. Néanmoins, ici on utilisera aussi des aplats de couleurs, car nos réflexions peuvent s'appuyer sur ces deux représentations. D’ailleurs, dans le domaine de la statistique spatiale, il est courant d’utiliser tous les types de représentation pour explorer les données, l’objectif n’étant pas dans ce cadre de respecter des règles cartographiques. Quoi qu'il en soit, cela fait 8 cartes, car il y a 8 représentations. La statistique multivariée peut contribuer à simplifier cette situation. Par exemple, ci-dessous, les deux cartes se ressemblent... Il est peut-être pertinent de les agréger. Vous pouvez tester cela par vous-même, en créant vos propres cartes. Peut-être allez-vous trouver d’autres cartes relativement ressemblantes ?
Faire votre carte avec des symboles proportionnels
A priori, à part pour les agriculteurs qui ont une répartition très singulière et éventuellement les cadres où l’importance de la concentration francilienne (en particulier à Paris) peut attirer le regard et masquer les ressemblances, les cartes se ressemblent toutes. En effet, quand on travaille sur les stocks, le facteur explicatif premier est souvent le poids des objets géographiques. Par conséquent, sans surprise, les CSP se concentrent où se concentrent les actifs et plus généralement la population… Cette réalité est particulièrement criante avec les aplats de couleurs, car la taille des symboles proportionnels peut complexifier les comparaisons. L'utilisation des quantiles peut même permettre de faire fi des différences liées à la forme des distributions statistiques (ici, comparer les cadres avec les autres CSP).
Corrélation et régression linéaire comme mesure de redondance
La corrélation est une mesure, une valeur quantitative. Elle mesure la force de l'intensité du lien entre deux variables (entre deux séries statistiques). La corrélation se calcule uniquement entre deux variables. C'est donc un point d'entrée de la statistique multivariée, on parle alors de statistique bivariée. La notion de corrélation se prête bien à une représentation graphique en deux dimensions : le nuage de points. Si l'on ne part pas d'une formalisation mathématique, pour comprendre la notion de corrélation, il semble nécessaire de comprendre parfaitement ce que représente un nuage de points. Dans ces graphiques, on trouve en abscisse (l'axe horizontal) une variable explicative nommée X et en ordonnée (l'axe vertical) une variable à expliquer nommée Y. On dit que l'on représente Y en fonction de X. Ci-dessous, chaque point du nuage représente un département et ces départements sont positionnés dans le nuage de points en fonction de leur nombre d'agriculteurs horizontalement et de leur nombre d'artisans verticalement. Si besoin, passez sur les points pour comprendre :
Ci-dessus le graphique dessine un nuage, c'est à dire une forme difficilement interprétable. Ce nuage, qui implique la catégorie des agriculteurs (qui est une catégorie singulière dans sa répartition spatiale), correspond donc à une situation où il n'y a a priori pas de liens entre ces deux variables. En revanche, si l'on fait la même chose pour d'autres variables, comme les employés et les professions intermédiaires, la situation diffère. Le nuage de points dessine en fait une forme plus simple, en l'occurrence celle d'une droite, c'est un peu ce que l'on recherche lorsque l’on mesure de la corrélation linéaire. Plus généralement, si le nuage de points prend une forme simple, il y a un lien entre les deux variables, une corrélation : on peut expliquer Y à l’aide de X et inversement.
Ce qu'il faut comprendre ici, c'est que cette représentation sous la forme d’un nuage de points (permise par le fait que nous travaillons uniquement sur deux variables) permet d'illustrer simplement la notion de liens (de corrélation) entre deux variables. Si votre nuage prend la forme d'une droite (ce que l'on cherche ici, car on travaille sur la corrélation linéaire), c'est qu'il y a un lien statistique entre les deux variables. On pourra expliquer (retrouver, estimer les valeurs de) l'une par l'autre. Cartographiquement, cela se traduit par le fait que les cartographies de ces variables seront très similaires (ou alors - plus compliqué à comprendre - totalement opposées on y reviendra). En effet, un lien fort statistiquement (une corrélation), c'est une redondance d'information, qui se traduit cartographiquement par des cartes qui se ressemblent. Essayez pour vous-même, ci-dessous si vous avez identifié au préalable d'autres variables aboutissant à des cartes similaires vous devriez voir des nuages de points qui ressemblent à des droites (ou à d'autres formes simples comme des courbes).
Désormais, on peut introduire la notion de régression linéaire qui va simplement rassembler l’ensemble des méthodes permettant de trouver la meilleure représentation possible d'un jeu de données à l'aide d'objets linéaires (droites, plans ou hyperplans). A noter que la régression linéaire modélise le lien entre une variable à expliquer et une ou plusieurs variables explicatives, elle n’est pas uniquement bivariée contrairement à la corrélation. Sachant que nous nous intéressons ici à la relation entre uniquement deux variables, la régression linéaire va nous permettre de dessiner (de modéliser) la droite qui approxime au mieux un nuage de points. On l'a vu plus haut, le nuage de points des employés en fonction des professions intermédiaires ressemble vraiment à une droite, la régression cherche à identifier cette droite, comme ci-dessous :
Ce qui est important à comprendre ici, c'est que même dans le cas où votre nuage de points n'a pas la forme d'une droite (comme dans le cas des artisans en fonction des agriculteurs), il est possible de chercher la meilleure représentation de ce nuage de points sous la forme d'une droite. Dans ce cas, cela peut permettre d'identifier des tendances un peu cachées, des tendances difficilement observables : attention néanmoins à ne pas surinterpréter cette tendance.
Une droite, c'est une équation du type Y = a X + b. La régression linéaire permet donc de calculer les meilleurs coefficients a et b de cette droite que l'on peut alors simplement dessiner. Quel est le lien avec la corrélation ? C'est simple, plus votre droite traduit bien la tendance de votre nuage de points (moins les points s'écartent de votre droite, plus votre nuage ressemble à une droite), plus la corrélation sera forte. Généralement, on donnera plutôt le carré du coefficient de corrélation (le R²) appelé coefficient de détermination. Le R² est une valeur facilement interprétable comprise entre 0 et 1 et peut s'exprimer en %. Un R² de 10% implique une droite qui s'ajuste relativement mal à vos données (la corrélation est faible). En revanche, un R² de 90% implique une droite qui colle bien aux données (la corrélation est forte). Testez par vous-même ci-dessous comment évolue ces valeurs en fonction des nuages de points étudiés :
Mesurer la corrélation entre différentes relations
Le coefficient de détermination (le carré de la corrélation) correspond donc en quelque sorte à la précision de votre droite (de la régression linéaire) à approximer votre nuage de points. C’est plus précisément le % de variation (de votre variable à expliquer) reconstitué par votre régression. La corrélation est une valeur plus riche et moins facilement interprétable que le R². La corrélation r est une valeur comprise entre -1 et 1. Elle est donc positive ou négative. Elle sera négative si votre droite décroit et positive si votre droite est croissante. Dans le cas d'une corrélation positive, quand X est faible Y est faible aussi, quand X est fort Y est fort aussi. Dans le cas d'une corrélation négative, quand X est fort Y est faible, quand X est faible Y est fort.
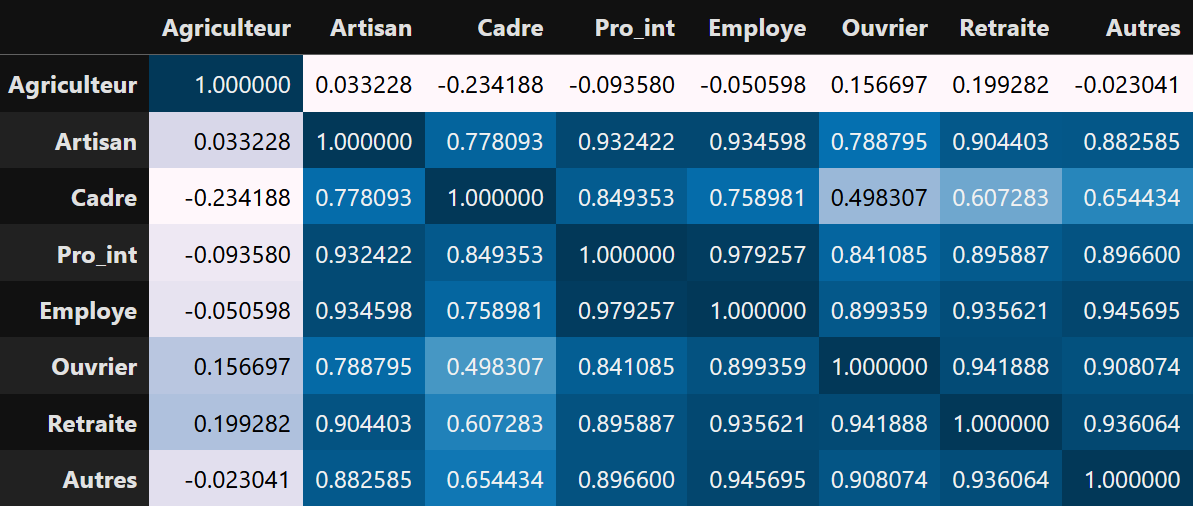
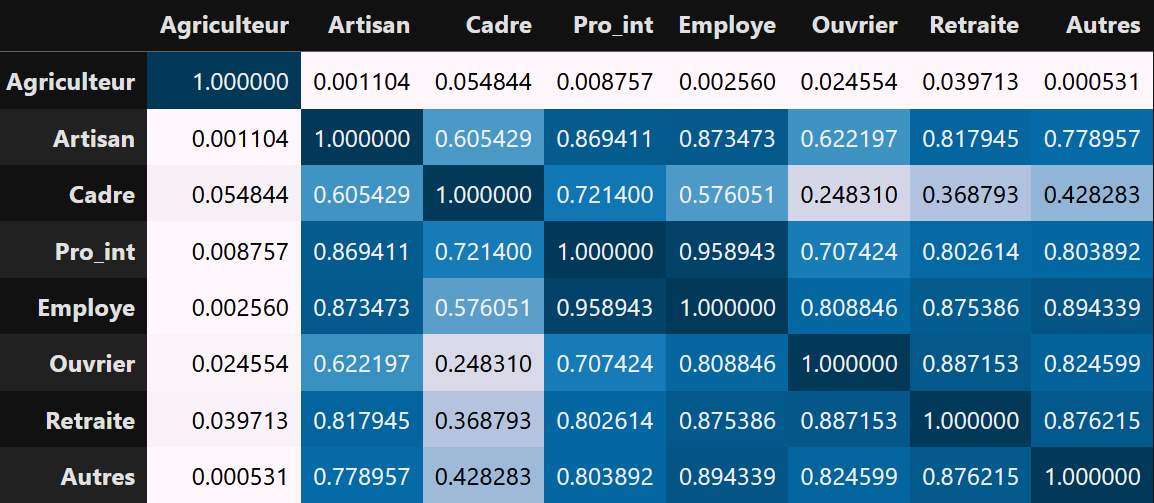
Plus votre R est proche de zéro, plus votre corrélation est faible, on pourra même parfois dire qu’elle est nulle. Quoi qu’il en soit, en combinant le R² avec le coefficient directeur de la droite, on arrive aux mêmes conclusions. Que ce soit le R ou le R² ce sont des mesures continues, ce sont des gradients. Ils ne sont pas binaires, les résultats ne sont pas du type : il y a corrélation ou il n’y a pas corrélation. Les résultats sont plutôt du type : il y a une forte corrélation, il y a une très faible corrélation, elle est quasiment nulle. C’est pourquoi les graphiques ci-dessus affichent aussi la p-value. Ici, plus votre R² est élevé, plus votre p-value sera faible. La p-value peut être interprétée comme la probabilité que votre R² puissent être retrouvé en prenant des variables au hasard. Ainsi, si l’on veut conclure de manière binaire à l’existence ou non d’une corrélation on s’appuiera sur cette valeur. En SHS, ce seuil est de 5%. Si votre p-value est inférieure à 0.05, on conclura à l’existence d’une corrélation, sinon on conclura à l’absence de corrélation. Enfin, pour synthétiser les résultats, on peut établir des matrices (des tableaux) de corrélation et de R² pour synthétiser l'ensemble des relations entre les variables.
Matrice de corrélation des variablesMatrice de R² des variables
A l’aide de ces tableaux, on voit clairement que la répartition des agriculteurs est la moins bien corrélée aux autres CSP. C'est pourquoi la cartographie de cette répartition apparait comme différentes des autres. On notera que c'est aussi la seule CSP qui est caractérisée par plusieurs corrélations négatives, dont une qui est faible mais semble statistiquement significative (p-value < 0,05) avec les cadres. Ainsi, les départements avec beaucoup d'agriculteurs ont tendance à être caractérisé par un faible nombre de cadres (comme par exemple, les Côtes-d'Armor et l'Aveyron). Au contraire, les départements avec beaucoup de cadres ont tendance à concentrer peu d'agriculteurs (comme Paris et les Hauts-de-Seine).
Les résidus
Quand on parle de régression et de corrélation, il y a une notion centrale cachée. C'est celle de résidus. Un résidu est simplement l'écart entre une donnée (un point) et la droite de régression. Plus précisément, graphiquement c'est l'écart vertical entre cette donnée (ce point) et la droite. Tous les points sont alors caractérisés par un écart vertical avec la droite de régression. Quand on représente ces écarts (ces résidus) sur le nuage de points (en rose ci-dessous), on comprend vite que quand la droite s'ajuste bien au nuage de points, il y a globalement moins de résidus que lorsque le nuage de points ne ressemble pas à une droite. Effectivement, plus les résidus sont importants, plus le R² est faible. Inversement, moins les résidus sont importants, plus le R² est fort. Dans le dernier cas, il faut même zoomer sur le graphique pour voir apparaitre les résidus (essayez avec la molette sur le graphique de droite par exemple).
Quand le point est au-dessus de la droite, le résidu est positif. En revanche, quand le point est en-dessous de la droite, le résidu est négatif. Pour comprendre l'intérêt de cette remarque anodine, il faut ici bien comprendre que la droite est en quelque sorte une prédiction de la variable Y réalisée à partir de la variable X. Ainsi, si je m'intéresse à un cas où la corrélation est plutôt forte entre deux variables, il y a donc a priori une corrélation entre les deux variables et chercher à retrouver Y à partir de X ne semble pas déraisonnable. Or, on l’a vu plus haut, la régression permet de trouver les paramètres a et b de la droite qui lie X et Y. Par conséquent, en utilisant ces valeurs, on peut effectivement effectuer une prédiction.
Prenons le cas de la relation profession intermédiaire (variable à expliquer Y) employé (variable explicative X). Dans ce cas, a = 0.905423 et b = -6785.23 (vous pouvez retrouver ces valeurs dans le graphique dynamique), comme Paris possède 252 536 employés, on peut estimer que le nombre de professions intermédiaires est de 0.905423 x 252 536 – 6 785.23 = 221 866,67. Le résidu, c'est à dire l'écart entre la réalité (Paris possède 281 989 professions intermédiaires) et l'estimation, est de 60 123 (281 989 – 221 866). Ici, il y a plus de professions intermédiaires qu'estimés. C’est l’opposée pour la Seine Saint-Denis, essayez de retrouver par vous-même le résidu. Sinon, ci-dessous, retrouvez les premiers calculs de résidus pour estimer le nombre de professions intermédiaires d'un département à partir de son nombre d'employés.
La somme de tous les résidus permet de quantifier l'écart entre la droite et les données. Plus précisément, pour éviter que les écarts se compensent, on utilise la somme quadratique de ces écarts (on élève au carré les écarts avant de les additionner). Dans les faits, les méthodes de régression cherchent à trouver les coefficients de la droite qui minimisent cette somme quadratique : on parle de méthode des moindres carrés. On peut même retrouver la valeur du R² en s'appuyant sur cet écart, car le R² représente la proportion de la variance totale de la variable dépendante (Y) qui est expliquée par le modèle de régression.
Ainsi, dans le tableau complet ci-dessous la somme totale des carrés vaut : 14911805533,66. Ça peut paraitre beaucoup et effectivement ça l’est, c'est la quantification de l'erreur totale commise en réduisant le nuage de points sous la forme de la droite de régression. Néanmoins, initialement, la variation de Y (des professions intermédiaires) est encore plus grande. En effet, dans le tableau de résumé statistique du début, on peut voir que l’écart-type des professions intermédiaires est de 61831,76, la variance est donc de 61831,76². En multipliant cette valeur par le nombre d'objets géographiques (ici 96), on quantifie la variation que devait reconstituer notre droite de régression à : 96 x 61831,76². En faisant le rapport entre ces grands chiffres, on obtient la part de variation non expliquée par la droite (14911805533,66/(96*61831.76²) = 0,0411). Le r2 c'est 1 - ce rapport (1-0,0411 = 0, 9589 soit 95.89%) ! Testez ci-dessous comment évolue le R² avec d'autres valeurs de a et de b. C’est impossible d’obtenir un meilleur R², c’est-à-dire impossible d’obtenir une somme des résidus au carré plus faible.
Voir le tableau des résidus complet et tester d'autres paramètres
On peut alors exploiter ces résidus et les cartographier comme ci-dessous. En termes d'interprétation, sachant que les professions intermédiaires constituent une catégorie plus favorisée que les employés, puisqu'elle a été créée afin de caractériser une catégorie intermédiaire entre les employés et les cadres, on peut considérer les départements ayant un résidu positif comme plus privilégiés que ceux ayant un résidu négatif. Dans ce cadre, on pourra simplement interpréter la différence entre le département de la Seine Saint-Denis et Paris (ou encore avec les Hauts-de-Seine et les Yvelines). Néanmoins, ce n'est pas la seule grille de lecture permettant d’interpréter les résultats. Par exemple, les départements de l'arc méditerranéen possèdent des résidus négatifs remarquables. Cela est principalement lié à la surreprésentation des artisans (affichez les graphiques artisans en fonction des employés ou artisans en fonction des professions intermédiaires pour le vérifier) voire des retraités dans ces départements. Or, l’artisanat implique généralement peu de professions intermédiaires, mais plutôt d’éventuels employés (dans les aspects commerciaux).
Cette carte des résidus dégage aussi des clusters spatiaux intéressants : ancienne région Rhône-Alpes, départements côtiers majoritairement remarquables... Bref, cette carte est beaucoup plus riche que celles représentant simplement les deux CSP prises indépendamment. Enfin, on appréciera la volonté de ne pas surinterpréter les résidus légèrement positifs ou négatifs en privilégiant une carte avec une classe neutre (-5000;5000) qui rassemble la majorité des départements puisque la corrélation entre ces deux CSP est forte. On retrouve ainsi logiquement peu de départements s’écartant de la tendance générale : pour de nombreux départements, on peut assez bien estimer le nombre de professions intermédiaires à partir du nombre d’employés et il y a donc peu de départements atypiques pour cette relation.
Eviter les pièges
Corrélation et régression linéaire sont des outils très puissants qu'il faut utiliser avec précaution, car de grands pouvoirs impliquent de grandes responsabilités. Si la puissance de ces méthodes ne vous saute pas aux yeux, il est possible de revenir sur l'intérêt de ces méthodes.
Révisions
Corrélation et régression linéaire sont des outils très puissants qu'il faut utiliser avec précaution, car de grands pouvoirs impliquent de grandes responsabilités. Si la puissance de ces méthodes ne vous saute pas aux yeux, revenons sur l'intérêt de ces méthodes. Premièrement, on l'a vu plus haut, corrélation et redondance sont synonymes. Ainsi, en géographie, si deux variables sont redondantes, on se questionnera sur la pertinence de cartographier ces deux variables dans des cartes indépendantes. Or, généralement, les cartes à produire pour étudier un territoire ne manquent pas : pouvoir identifier des redondances est donc extrêmement intéressant pour limiter cette production cartographique et plus généralement simplifier l’analyse territoriale. D'ailleurs, lorsque l'on travaille sur des données de stock, ces redondances sont fréquentes et le travail sur ce type de données apporte généralement peu d'informations remarquables, notamment lorsque l'on connait les territoires sur lesquels on travaille. Etudier les résidus d'une régression apporte alors plus de subtilité dans les analyses, en identifiant les objets géographiques suivant la tendance générale de ceux plus atypiques.
Enfin, il y a un point sur lequel nous n'avons pas insisté jusqu'à maintenant. On a présenté succinctement, que derrière les régressions et les corrélations, il y avait l'idée de produire des modèles qui permettaient de faire des prédictions. Dans les faits, c'est l'intérêt premier de ces méthodes : avoir des modèles explicatifs, des modèles prédictifs des variables étudiées. On parle d'ailleurs de variable à expliquer et de variables explicatives. Ainsi, la corrélation, et plus généralement la régression linéaire tient une place centrale dans la démarche scientifique (même si justement on verra que corrélation statistique n'est pas équivalent à causalité). Il est compréhensible que si statistiquement on arrive par exemple à montrer simplement que quand X augmente Y augmente aussi, et que si derrière ce constat il y avait des hypothèses sérieuses nous ayant amené à tester cela, on aura une justification supplémentaire pour dire que c'est parce que X augmente que Y augmente... Bref, corrélation et régression permette de prédire des phénomènes, de valider des hypothèses, cela est juste fondamental dans une démarche scientifique, dans la compréhension des phénomènes qui nous entourent.
Néanmoins, dans cette dernière partie, nous allons insister sur les limites et les défauts de ces approches. On peut tout d'abord s'interroger sur le fait que toutes les CSP sont plutôt fortement corrélés entre elles (sauf les agriculteurs) alors que l’on pourrait s'attendre à ce que certains départements concentrent plus d'ouvriers que de cadres, que d'employés... Après tout, ça devrait être un système de vases communicants. Lorsque l’on analyse les résidus d'une relation, on commence en effet à entrevoir cela, néanmoins utiliser ces méthodes pour quelque chose d'aussi simple peut interroger. Ces corrélations s’expliquent par le fait que l'on travaille sur des données de stock. Or, les données de stock tendent à mal retranscrire les tendances thématiques et sont très fortement influencées par les caractéristiques primaires des objets géographiques : la taille et le poids. Ainsi il y a un facteur confondant qui explique ces nombreuses corrélations : la population active de ces départements. En effet, quel que soit la CSP étudiée, les départements les plus peuplés ou plus précisément ceux possédant le plus de personnes actives, vont être ceux qui ont le plus d'employés, de professions intermédiaires... De même, les départements qui ont le moins d'actifs auront le moins d'employés, de professions intermédiaires...
Visualiser le lien entre les CSP et le nombre d'actifs des départements
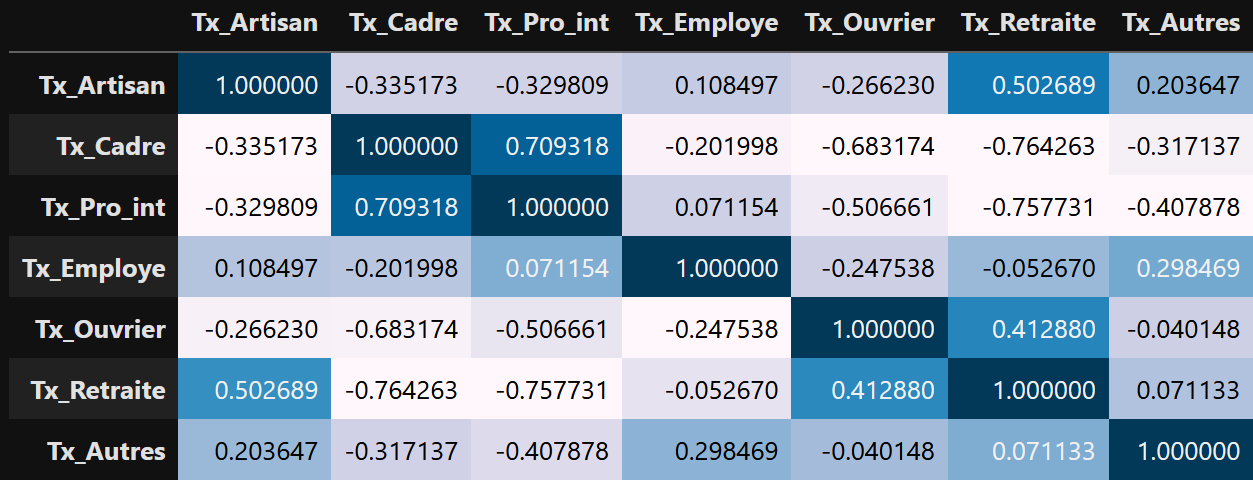
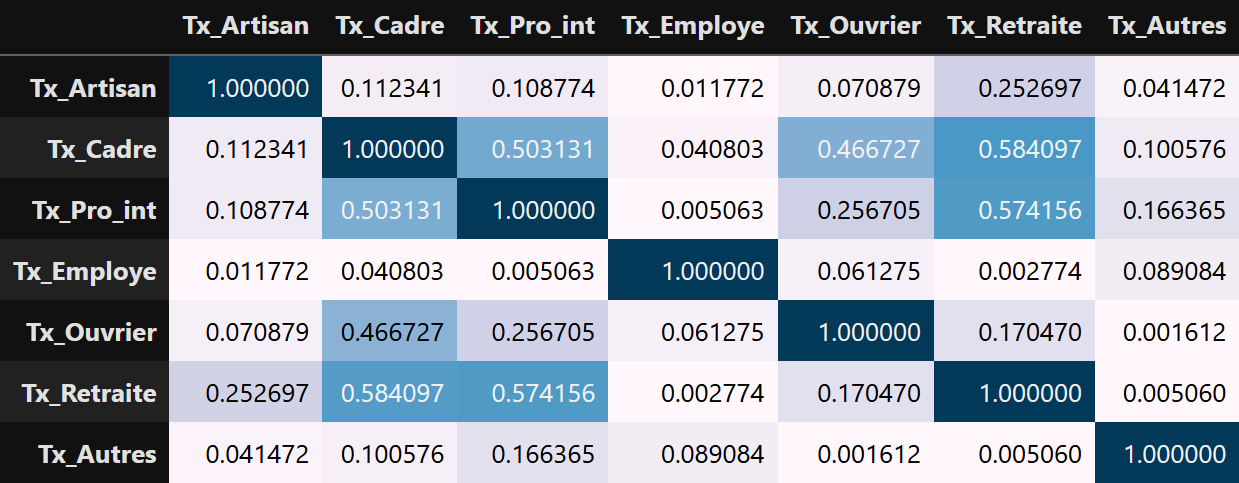
Si l’on reprend les mêmes analyses, les mêmes calculs, non pas sur les stocks, mais sur les taux, la situation est tout de suite plus complexe, plus riche. Les résultats peuvent même être totalement inversés. Par exemple, la corrélation entre le taux d'employés et le taux de profession intermédiaire est en fait quasi nulle. Les corrélations sont globalement moins marquées avec les taux : R² tous inférieurs à 60%. Les corrélations négatives sont aussi plus nombreuses. La corrélation la plus marquée est même négative entre le taux de retraité et le taux de cadre : plus taux de cadre d’un département est élevé, plus son taux de retraité est faible.
Tableau de corrélation et de R² entre les taux des CSP
Matrice de corrélation des variables
Matrice de R2 des variables
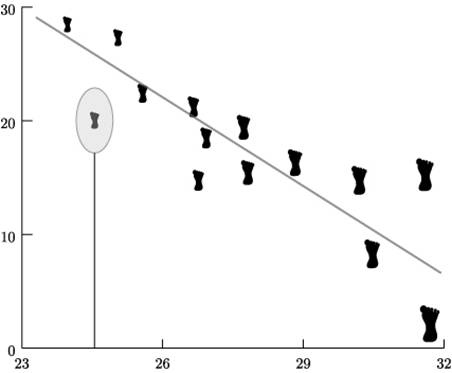
Cela ne veut pas dire qu'il ne faut pas travailler sur des données de stock. Typiquement, il est très intéressant de constater que les agriculteurs ne suivent pas du tout la même logique de distribution que les autres CSP. Ici, il faut comprendre qu'il peut exister des facteurs autres pouvant expliquer les corrélations : ce que l’on appelle des facteurs confondants. Il y a un exemple que je donne souvent en cours pour illustrer cela : si vous prenez dans une cour de récréation d’école primaire des élèves et que vous leur faites passer une même dictée et que dans le même temps vous relevez leur taille de pieds, il est très probable que vous puissiez établir une corrélation négative entre la taille des pieds de ces élèves et leur nombre de fautes d'orthographe : plus les pieds sont grands, moins ils font de fautes. Néanmoins, la baisse du nombre de fautes d'orthographe et l'augmentation de la taille des pieds sont liés à l'âge. La même expérience à l'université marcherait beaucoup moins bien...
Facteur de confusionFautes d'ortographe en fonction de la taille des pieds (Nicolas Gauvrit, statistiques : méfiez-vous)
Corrélation n'est donc pas simplement égale à causalité. Il faut en fait tout un ensemble d'hypothèses concordantes pour qu'une corrélation prenne sens. Le lien statistique entre augmentation des températures et augmentation des émissions de CO2 n'est pas suffisant pour prouver/établir l'existence de ce lien, il faut tout un ensemble de théories et d'hypothèses qui mises conjointement permettent de conclure qu'il existe une forte probabilité que ce lien soit réel. Bref, c'est compliqué... C'est pourquoi, on a commencé à aborder les notions de corrélation et de régression par des questions plus simples de redondance, de ressemblance...
Le deuxième piège consiste à questionner l'idée de relation linéaire. En effet, il existe d'autres types de relation. Les nuages de points peuvent prendre des formes multiples, comme des courbes ou des vagues (plus généralement des fonctions non monotones). Par exemple, au cours d'une journée, les températures varient généralement de manière non linéaire, si vous testez la corrélation linéaire entre l'heure de la journée et les températures vous trouverez a priori une corrélation nulle. Pourtant, il existe bien une forme simple dans l’image ci-dessous prise au hasard : celle d'une fonction sinusoïdale. Bref, si on ne représente pas les données, on peut passer à côté de relations plus subtiles ou plus complexe que la simple relation linéaire.
Température au cours de la journéeTempérature en fonction de l'heure de la journée
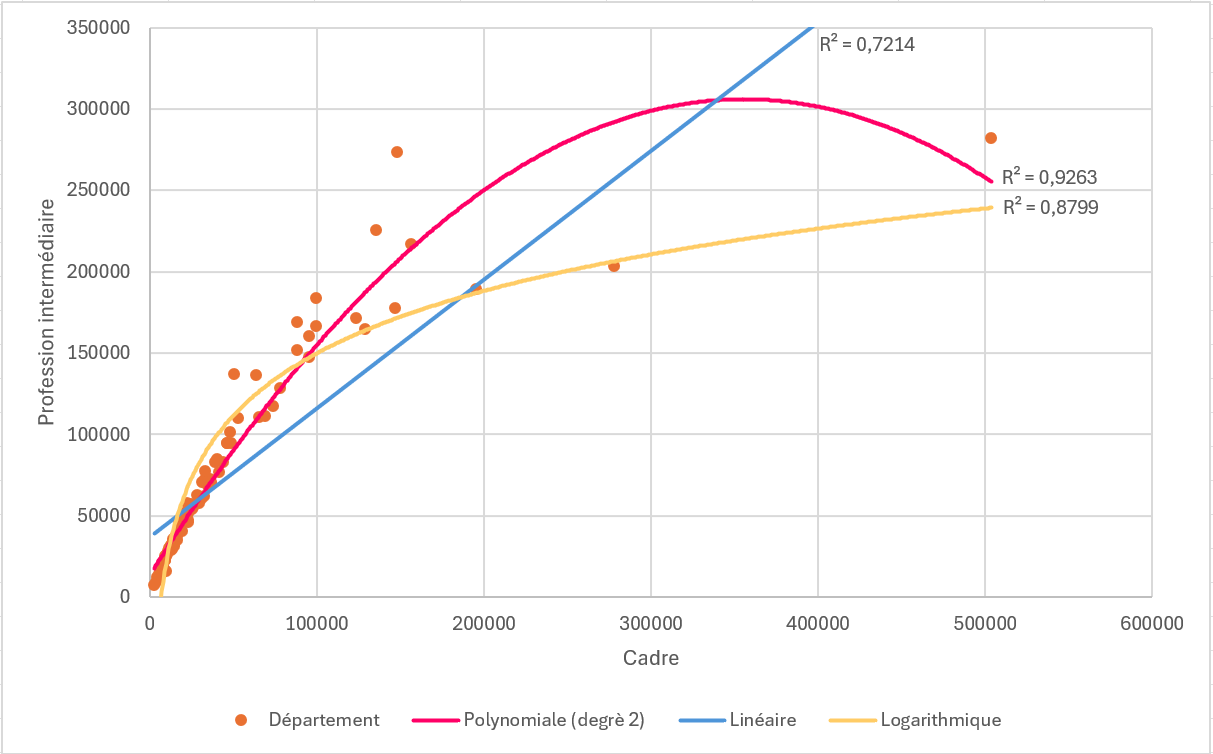
Dans notre jeu de données, en cherchant uniquement des relations linéaires, on peut sous-estimer la force des liens entre des variables. Par exemple, ci-dessous, dans le cas de la relation entre les professions intermédiaires et les cadres, on peut visualiser comment le R² varie selon la fonction choisie. Cette relation est très forte, presque aussi forte que celle entre les employés et les professions intermédiaires sur laquelle on a insisté, si on considère une relation polynomiale et non une relation linéaire.
Relation non linéaireProfessions intermédiaires en fonction des cadres
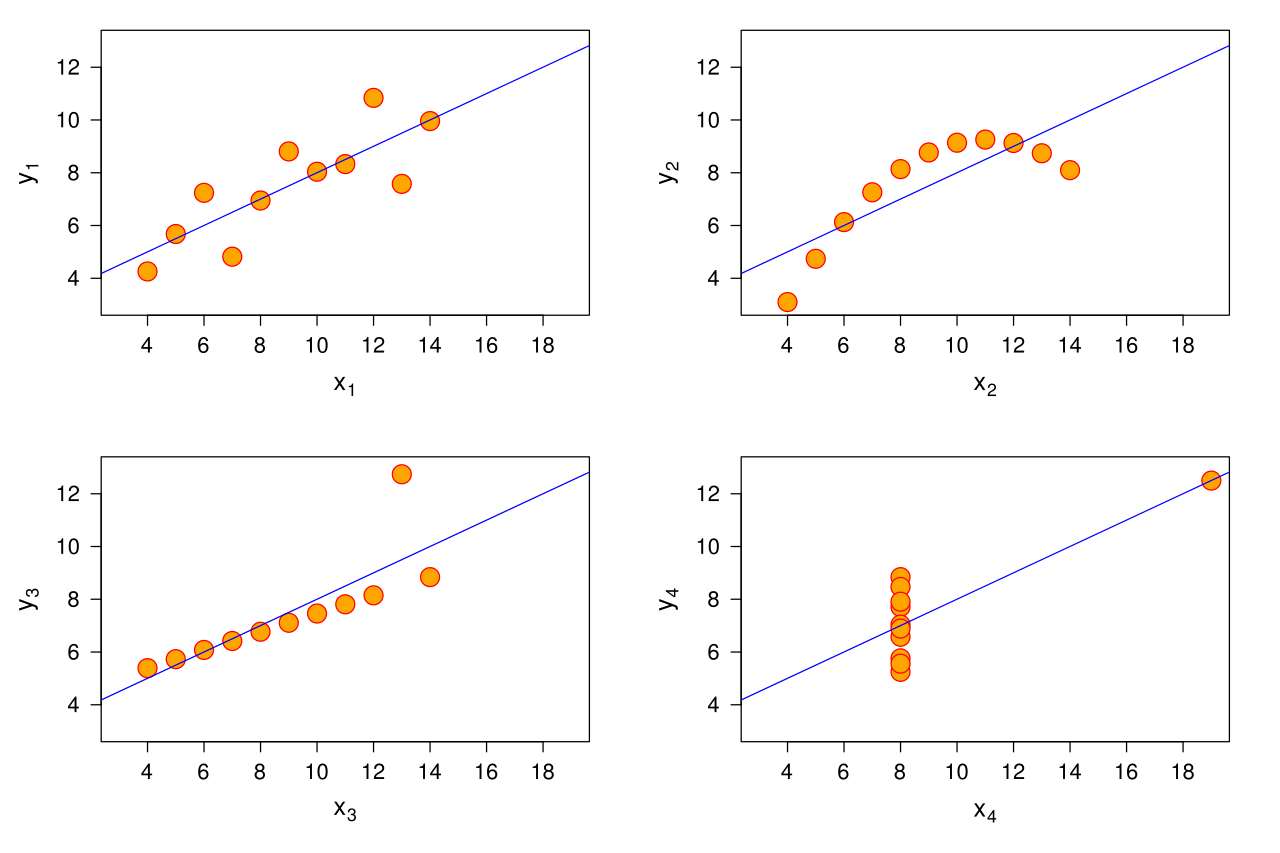
Autre élément important par lequel on peut terminer, un même R² et une même régression peuvent correspondre à des situations très différentes. On cite souvent le quartet d'Anscombe pour illustrer ces situations. Il y a ainsi une situation plutôt recherchée où le R² traduit bien la nature de la relation entre X et Y. Une autre correspond simplement au cas d'une relation non linéaire. Les deux autres cas sont plus difficiles à traiter. Ils relèvent de la thématique des points aberrants. En effet, n'importe quelle mesure peut être influencée par des objets au comportement atypique, voire à l'erreur de mesure.
La quartet d'AnscombeQuatre régressions équivalentes : Y = 0,5 x + 3 ; R² = 0,816
Dans nos données, il n'y a pas d'erreur de mesure : il y a des imprécisions, mais pas d'erreurs grossières a priori. En revanche, si on prend le cas de la variable cadre, qui est caractérisée par une très forte présence à Paris, voire dans les Hauts-de-Seine et les Yvelines, certaines relations peuvent être sous-estimée ou surestimée par ce comportement atypique. Par conséquent, soit on admet cela et on ne le corrige pas, car on juge que cela retranscrit fidèlement ce qui se passe, soit on essaye de lutter contre en supprimant les points aberrants afin de vérifier que l'on ne passe pas à coté de quelque chose. Ainsi, ci-dessous, vous trouverez une comparaison entre les cadres et les retraités et entre les cadres et les employés, avec d’une part tous les départements de France métropolitaine et d’autre part ces mêmes départements sans Paris, les Hauts-de-Seine et les Yvelines. Les résultats sont alors fondamentalement différents.